Big data กับ วงการยา ตอนที่2
หลังจากที่ได้นำเสนอเรื่อง Big Data Analytic ในวงการยา
ก็มีหลายท่านถามมาเยอะว่า
หลังจากได้ลองหาข้อมูลเพิ่มเติมแล้ว อยากจะรู้เรื่องนี้
มันจะใช้เทคนิคอะไรยังไงนะ หรือ ปัญหาแบบนี้ มันคืออะไรกันแน่
ออกตัวก่อนว่า ไม่ได้เป็นผู้เชี่ยวชาญด้าน Big data ขนาดที่จะตอบได้โดยไม่ต้องหาข้อมูล เลยไปหาข้อมูลจาก หนังสือชื่อว่า Data Science for Business มาแบ่งบันกัน
ซึ่งหนังสือได้แบ่งการวิเคราะห์ออกเป็น 9 ประเภท ดังนี้

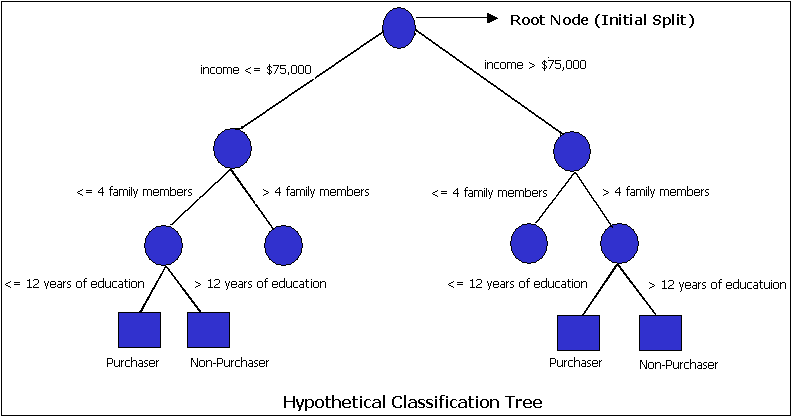
1. Classification
Classification เป็นเทคนิคจำพวก Supervised Learning คือ
ต้องมีข้อมูลที่มีทั้ง X และ Y ไว้สร้างโมเดล โดยค่า Y ที่เราสนใจนั้น
จะเป็นตัวแปรประเภท Categorical หรือ เป็นตัวแปรกลุ่ม
ตัวอย่าง เช่น
- -สร้าง Credit Scoring Model ขึ้นมา โดยทางแผนก OTC จะได้ใช้ประโยชน์
ในการทำนายว่า หนี้อันนี้จะเป็นหนี้ดีหรือหนี้เสีย - -ทำ Churn Prediction ใช้บ่อยในวงการ โทรศัพท์มือถือ เพื่อทำนายว่าลูกค้าจะย้ายค่ายหรือเปล่า
เทคนิคที่ใช้ ก็มีตั้งแต่ Decision Tree หรือ Logistics Regression
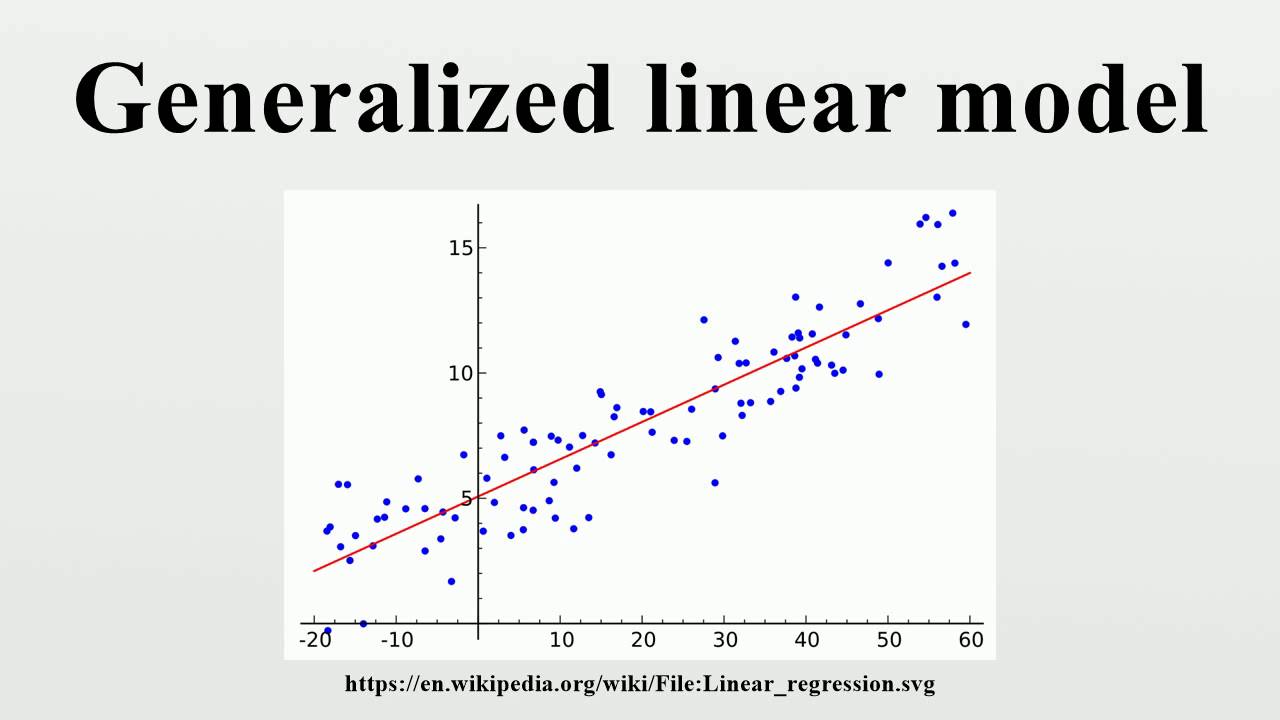
2. Regression
เป็นเทคนิค Supervised Learning อีกจำพวกหนึ่งที่ตัวแปร Y เป็นค่าตัวเลข โมเดลนี้จะทำการพยากรณ์ค่าออกมาเป็นตัวเลขเลย เช่น
พยากรณ์ยอดขาย พยากรณ์ปริมาณลูกค้า
พยากรณ์ยอดขาย พยากรณ์ปริมาณลูกค้า
ความซับซ้อนของการทำโมเดลประเภทนี้ คือ ตัวแปร X มักจะต้องอยู่ในช่วงเวลาที่เกิดก่อนตัวแปร Y เพราะถ้าตัวแปร X ที่เกิดขึ้นในช่วงเวลาเดียวกับ Y
มาใช้พยากรณ์นั้น จะเหมือนเอาเฉลยมาใช้ในการพยากรณ์
มาใช้พยากรณ์นั้น จะเหมือนเอาเฉลยมาใช้ในการพยากรณ์
ตัวอย่าง เช่น
- พยากรณ์ความต้องการในการใช้ Product (Product Manager ใช้บ่อย)
- พยากรณ์ยอดขายของผลิตภัณฑ์ (อันนี้แผนกขาย ใช้บ่อย)
เทคนิคที่ใช้ ได้แก่ Regression ประเภทต่างๆ หรือพวก Time-series Models

3. Causal Modeling
ต้องบอกก่อนว่า “correlation does not imply causation” หรือ
การที่ตัวแปรสองตัวมีค่าความสัมพันธ์กันนั้น ไม่ได้แปลว่า
ตัวแปรหนึ่งส่งผลต่อตัวแปรหนึ่ง
ถ้าอยากรู้ว่า ตัวแปร X ทำให้เกิด Y จริงๆ ก็ต้องไปทำ
Causal Modeling
ซึ่งจะต้องควบคุมผลกระทบของปัจจัยอื่นๆ อีก
โดยมากจะทำเป็น Experiment Design
การที่ตัวแปรสองตัวมีค่าความสัมพันธ์กันนั้น ไม่ได้แปลว่า
ตัวแปรหนึ่งส่งผลต่อตัวแปรหนึ่ง
ถ้าอยากรู้ว่า ตัวแปร X ทำให้เกิด Y จริงๆ ก็ต้องไปทำ
Causal Modeling
ซึ่งจะต้องควบคุมผลกระทบของปัจจัยอื่นๆ อีก
โดยมากจะทำเป็น Experiment Design
ตัวอย่าง เช่น
- การทำ A/B Testing เพื่อทดสอบว่า Feature ไหน มีผลต่อ
Conversion Rate มากกว่ากัน - ให้ลูกค้าทดลองกินไอศครีมหลายๆ รส โดยมีการ control ทั้งลำดับที่กิน
กินแล้วให้กินน้ำกับ cracker แล้วเลือกว่าชอบรสไหน
เพื่อทดสอบว่า รสไหนอร่อยสุด
เทคนิคที่ใช้ ก็พวก GLM (General Linear Modeling)
เช่นพวก ANOVA ANCOVA และอีกมากมาย (อันนี้ไม่เคยใช้ครับ)
เช่นพวก ANOVA ANCOVA และอีกมากมาย (อันนี้ไม่เคยใช้ครับ)
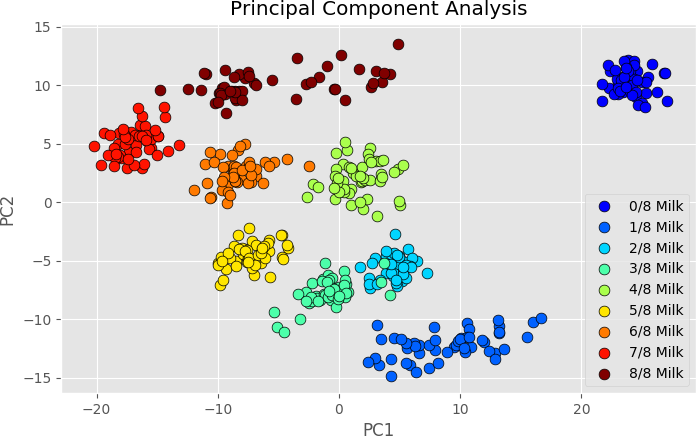
4. Data Reduction
เวลาเรามีตัวแปร X เยอะๆ พอเอาเข้าไปสร้างโมเดล บางทีเค้าก็ตีกันเอง
แย่งกันอธิบาย Y กันใหญ่ ทำให้มีปัญหาที่เราเรียกว่า Multicollinearity
บางคนก็เกิดอาการรักพี่เสียดายน้อง ไม่อยากทิ้งตัวแปรไหนไป
ก็เลยเอาตัวแปรเหล่านี้มาจัดการรวบเป็นกลุ่มใหม่ขึ้นมาซะ จาก 50 ตัวแปร
อาจจะเหลือจัดเป็นกลุ่มแล้วได้ซัก 5 ปัจจัย หรือ 5 Factors ก็ได้
แย่งกันอธิบาย Y กันใหญ่ ทำให้มีปัญหาที่เราเรียกว่า Multicollinearity
บางคนก็เกิดอาการรักพี่เสียดายน้อง ไม่อยากทิ้งตัวแปรไหนไป
ก็เลยเอาตัวแปรเหล่านี้มาจัดการรวบเป็นกลุ่มใหม่ขึ้นมาซะ จาก 50 ตัวแปร
อาจจะเหลือจัดเป็นกลุ่มแล้วได้ซัก 5 ปัจจัย หรือ 5 Factors ก็ได้
เทคนิคจากนี้เป็นต้นไปจะเป็นเทคนิคพวก Unsupervised Learning ละครับ
ก็คือ ข้อมูลที่ใช้ในการสร้าง Model นั้น ไม่จำเป็นต้องมี Y มาก่อน
ก็คือ ข้อมูลที่ใช้ในการสร้าง Model นั้น ไม่จำเป็นต้องมี Y มาก่อน
ตัวอย่าง เช่น
- เอาตัวแปรต้นของการพยากรณ์ความน่าจะเป็นในการซื้อสินค้า
มาจัดกลุ่มเป็นปัจจัย หรือ Factor (อันนี้ใช้ในการแบ่งประเภทของลูกค้า)
เทคนิคจำพวกนี้ ก็ได้แก่ Principle Component Analysis หรือ
Exploratory Factor Analysis
Exploratory Factor Analysis
5. Co-occurrences Grouping
เทคนิคการวิเคราะห์นี้ จะเป็นการดูว่าอะไรเกิดขึ้นพร้อมกันบ่อยๆ วิเคราะห์หาความน่าจะเป็นของการเกิดของสองสิ่ง สามสิ่ง หรือ หลายๆ สิ่ง พร้อมกัน
ตัวอย่าง เช่น
- หาว่าสินค้าไหนใน ร้านยา ถูกซื้อคู่กันบ่อยๆ
- เทคนิคเหล่านี้ เช่น Market Basket Analysis

6. Link Prediction
เป็นการวิเคราะห์ความเชื่อมโยงของเครือข่าย ว่าใครหรือของสิ่งไหนน่าจะมีความเชื่อมโยงไปยังอีกจุดหนึ่ง
ตัวอย่าง เช่น
- วิเคราะห์หาว่าเราควรจะรู้จักใครอีกในเครือข่ายนี้
(อันนี้ไม่ค่อยได้ใช้ในวงการยา)
เทคนิคเหล่านี้ เช่น Social Network Analysis

7. Similarity Matching
การวิเคราะห์ข้อมูลเพื่อหาว่าคนหรือสิ่งของคู่ไหน ที่มีลักษณะคล้ายคลึงกันบ้าง
ตัวอย่าง เช่น
- หาว่า Users คนไหนมีความคล้ายคลึงกัน เพื่อนำเอารูปแบบ
การซื้อของคนหนึ่ง ไปแนะนำให้อีกคนหนึ่ง - แนะนำผู้โดยสารว่า ควรไปเที่ยวที่ไหนดี โดยดูว่าผู้โดยสารคนนี้
มีลักษณะเหมือนผู้โดยสารคนไหนอีกบ้าง
เทคนิคเหล่านี้ เช่น Nearest Neighbor
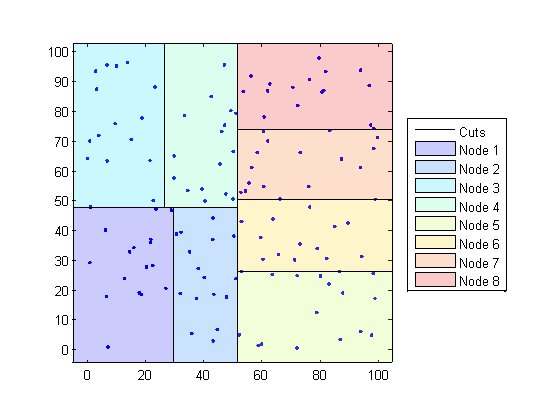
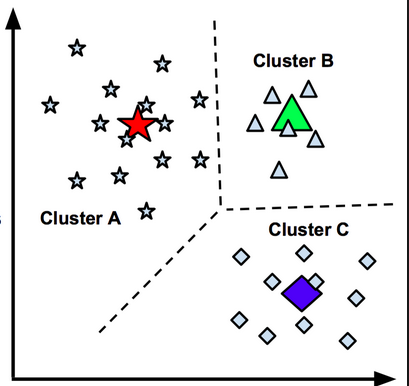
8. Clustering
เป็นการวิเคราะห์ข้อมูลเพื่อจัดกลุ่มคน หรือ สิ่งของ ที่มีลักษณะคล้ายคลึงกันให้อยู่ในกลุ่มเดียวกัน
ตัวอย่าง เช่น
- จัดกลุ่มลูกค้าตามพฤติกรรมการซื้อสินค้า
- จัดกลุ่มร้านค้าสาขา ตามรูปแบบการขายหรือประเภทลูกค้าที่เข้าร้าน
เทคนิคพวกนี้ ได้แก่ K-means Clustering
9. Profiling
เป็นการวิเคราะห์ข้อมูลที่ตรงไปตรงมา ไม่ซับซ้อน คือ การอธิบายลักษณะเด่นของสิ่งที่เราสนใจ โดยมาก ก็จะทำจากการหาค่าเฉลี่ยพฤติกรรมต่างๆ
ของคนในกลุ่ม หรือ เลือกตัวแทนกลุ่มที่น่าสนใจมาใช้อธิบายพฤติกรรมของกลุ่มนั้นๆ
ของคนในกลุ่ม หรือ เลือกตัวแทนกลุ่มที่น่าสนใจมาใช้อธิบายพฤติกรรมของกลุ่มนั้นๆ
ตัวอย่าง เช่น
- อธิบายพฤติกรรมหรือลักษณะเด่นของลูกค้าในแต่ละกลุ่ม
เทคนิคพวกนี้ ได้แก่พวก Descriptive Analysis ทั้งหลาย
(เช่น หา mean หา sum)
(เช่น หา mean หา sum)
ผมเชื่อว่าหลายท่านได้อ่านจนจบแล้วทั้ง9ข้อ อาจจะมึนหัวได้ ซึ่งจริงๆการทำData Analytic จะมีเรื่องของสถิติมาเกี่ยวข้องเสมอครับ
(ผมเองก็ไม่ชอบเป็นอย่างมาก 555) ซึ่งที่นำเสนอมาเพื่อให้ทางผู้ที่จะเริ่มวิเคราะห์ข้อมูลตัวเลขที่เรามี ได้รู้ถึงขอบเขตของการทำ Big Data Analytics ส่วนเราจะเลือกการวิเคราะห์แบบไหน อยู่ที่โจทย์ของเรามากกว่าว่าต้องการรู้อะไรหรือต้องการการวิเคราะห์ด้านไหนจากข้อมูลที่เรามีอยู่
(ผมเองก็ไม่ชอบเป็นอย่างมาก 555) ซึ่งที่นำเสนอมาเพื่อให้ทางผู้ที่จะเริ่มวิเคราะห์ข้อมูลตัวเลขที่เรามี ได้รู้ถึงขอบเขตของการทำ Big Data Analytics ส่วนเราจะเลือกการวิเคราะห์แบบไหน อยู่ที่โจทย์ของเรามากกว่าว่าต้องการรู้อะไรหรือต้องการการวิเคราะห์ด้านไหนจากข้อมูลที่เรามีอยู่
เช่น Sale Manager อยากทราบการพยากรณ์ยอดขายของลูกทีมแต่ละคน หรือ แต่ละโรงพยาบาล ก็อาจจะใช้Tool Regression และ Data Reduction ร่วมด้วยก็ได้ ซึ่งในProgram Rapid miner จะมี Tool ให้เราเลือกเยอะมาก แต่ก็จะครอบคลุมใน 9 ข้อนี้ทั้งนั้นครับ
สุดท้าย การทำData analytic ไม่ยากเกินไป ไม่ใช่ศาสตร์แห่งตัวเลขอย่างเดียว
แต่เป็นหลายๆศาสตร์ที่ผสมผสานกัน ขึ้นกับเจ้าของข้อมูลว่าจะใช้ประโยชน์ของข้อมูลที่เรามีได้เต็มประสิทธิภาพหรือเปล่า อย่าเป็นข้อมูลท่วมหัว ใช้ประโยชน์ไม่ได้ครับ
แต่เป็นหลายๆศาสตร์ที่ผสมผสานกัน ขึ้นกับเจ้าของข้อมูลว่าจะใช้ประโยชน์ของข้อมูลที่เรามีได้เต็มประสิทธิภาพหรือเปล่า อย่าเป็นข้อมูลท่วมหัว ใช้ประโยชน์ไม่ได้ครับ
เรียบเรียง
ภก.ภูริทัต ว่องพุฒิพงศ์


ความคิดเห็น
แสดงความคิดเห็น